
The first task is not a task at all – the attentive reader will have noticed in the headline, that our first stop on the road to web development is an introduction 😉

HTML, or HyperText Markup Language, is a markup language used to describe the structure of a web page. It uses a special syntax or notation to organize and give information about the page to the browser. Elements usually have opening and closing tags that surround and give meaning to content.
freecodecamp.org
There are already very good hints in this short paragraph to answer the question „What the heck is HTML?“. MDN starts a bit more vague:
HTML (HyperText Markup Language) is the most basic building block of the Web.
MDN web docs
However, this is quite right – without HTML the Web as we know it would not be the same. We could theoretically live without other building blocks such as CSS (which describes the visual presentation) and JavaScript (which describes functionality), but not without the general structure. As probably most of you know, the foundations of the Web were laid out in 1989 by the British physicist Tim Berners-Lee at CERN. In his proposal „Information Management: A Proposal“ he detailed the need for „linked information systems„, using the non-linear text system „hypertext„. The term hypertext, however, was coined decades before Berners-Lee’s proposal by Ted Nelson – around the 1950s.
While Berners-Lee created HTML in late 1991, it was not released until 1993. However, the first officially published specification was not HTML 1.0 but HTML 2.0 in the year 1995 – and can be read in all its glory in RFC 1866.
But I am losing myself in awesome tech-history 😉 Probably most important is the syntax of HTML: by using opening and closing tags the content of a page receives semantics, thus its meaning. freeCodeCamp provides the following example:
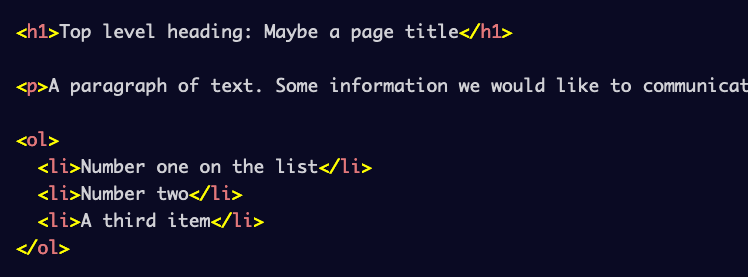
What this does is easily explained:
<h1>Top level heading: Maybe a page title</h1>This defines a primary headline of a page. Being the first of the six section heading elements (<h1>-<h6>) this headline represents an important part for every page. Therefore, this element should be chosen with care as it influences not „only“ the semantics of the page, but also how screen readers interpret the content within and how search engines rank the page.
<p>A paragraph of text...</p>Well, the text itself says it all: the <p> element defines a paragraph, grouping related content such as text, images and links together. Paragraphs are block-level elements, so they always start a new line and take up the full width available within their parent element. They also allow tag omission – meaning that the end tag can be omitted if another block-level element or no element follows within its parent.
<ol>
<li>Number one on the list</li>
<li>Number two</li>
<li>A third item</li>
</ol>The <ol> element defines ordered lists – with <li> elements representing the items of that list. Items within ordered lists are automatically numbered and can receive values as well as a type classification as attributes. While <li> elements support tag omission, the end tags of <ol> elements can’t be omitted.
As you can see, there is a lot that can be said about HTML elements; therefore, it’s quite obviously that writing its specifications is not a one-man-show. Founded by Tim Berners-Lee in 1994, the World Wide Web Consortium – W3C for short – is, looking for a better word, the „governing“ body organising the development of Web-related specifications.
While there is still much more to say about the HTML, the W3C and the Web, I think I will leave it with this. It’s just the first task after all 😉
Photo by Florian Olivo on Unsplash